The main difference between a simple LLM and an agent comes down to the system prompt.
The system prompt, in the context of an LLM, is a set of instructions and contextual information provided to the model before it engages with user queries.
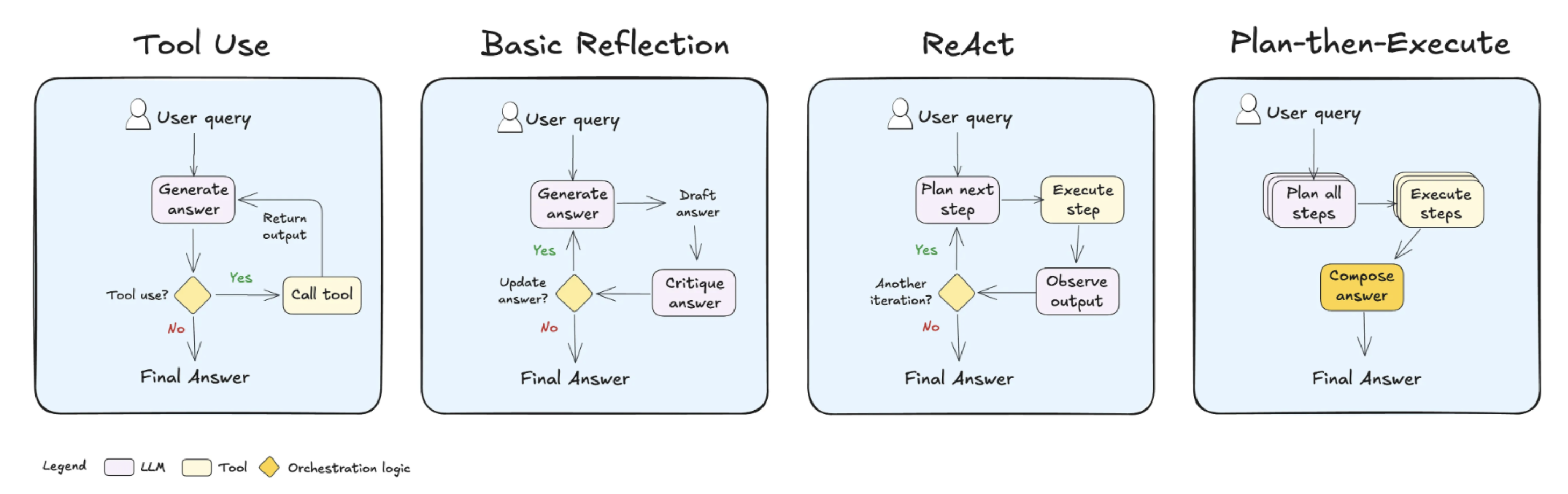
Common agentic patterns:
- Tool Use: The agent determines when to route queries to the appropriate tool or rely on its own knowledge.
- Reflection: The agent reviews and corrects its answers before responding to the user. A reflection step can also be added to most LLM systems.
- Reason-then-Act (ReAct): The agent iteratively reasons through how to solve the query, performs an action, observes the outcome, and determines whether to take another action or provide a response.
- Plan-then-Execute: The agent plans upfront by breaking the task into sub-steps (if needed) and then executes each step.
Reasoning Abilities:
• Multi-Step Reasoning: The agent should break down complex problems into smaller tasks and execute them in sequence. • Chain-of-Thought (CoT): Model a “thought process” internally before producing a final action or answer. • Statefulness: Keep track of the current context, results of previous steps, and what still needs to be done.
Tool Use:
The agent should be able to call external functions (tools) such as: • APIs or Web Requests: For live data retrieval (e.g., currency exchange rates, weather). • Databases: For querying structured information. • Search Engines: For knowledge retrieval. • Local Utilities: Such as calculators, file I/O operations, or other Python functions.
System Architecture
- Agent State & Memory: A structure to keep track of conversation history, intermediate steps, and results.
- Reasoning & Planning Module: A system that uses the language model to break down tasks into sub-steps.
- Tool Interface: A standardized way to define and call external functionalities (tools).
- Conversation Loop: A loop that:
- Provides the agent with the current context and objective.
- Lets the model produce a reasoning chain and/or decide on tools to call.
- Executes the chosen tools and feeds the result back into the model.
- Repeats until a final answer is produced.
Implementation
- Reasoning Loop Manually Coding a Reasoning Loop: Implement a loop where you: • Prompt a model for a reasoning step. • Interpret its output to decide next actions. • Provide the model with feedback and results of tool executions. • Continue until the problem is solved.
Example system message
You are an AI assistant with access to the following tools. You can use them by saying: "Use ToolName: [query]". Always think step-by-step, and when you have enough information, provide the final answer.
Step-by-Step Reasoning Protocol (e.g. ReAct/CoT): • In your prompts, you can encourage the model to produce reasoning in a structured manner. • For example, you might instruct it to output text in a JSON-like format or a clear pattern like:
Thought: <model's reasoning here>
Action: <name_of_tool> | <arguments>
- Tools Implementation: • Define a Python class or a simple dictionary that maps tool names to functions. • Each tool should have: • A name (string) • A description (string) • A run method (a callable that takes arguments and returns a result)
class Tool:
def __init__(self, name, func, description):
self.name = name
self.func = func
self.description = description
def run(self, *args, **kwargs):
return self.func(*args, **kwargs)- Prompt Design: • You need a system prompt that instructs the model how to behave. • You can include a list of available tools and instructions on how to use them. Example system prompt:
You are an assistant that can use tools.
Always follow this format:
1. Thought: Describe your reasoning process step-by-step.
2. If a tool is needed, write:
Action: <tool_name> | <arguments>
3. If you have enough information to answer, write:
Final Answer: <answer>
Available tools:
- search: use it to search the web. Use `Action: search | query`.
- calculator: use it to do math. Use `Action: calculator | expression`.
User prompt might be something like:
What is the capital of France? Then please provide the population of that city.
- Control Loop: The control loop is where the “agent” logic lives.
• Steps:
- Send the current conversation (system prompt + user prompt + any intermediate results) to the model.
- Parse the model’s response.
- If the response indicates an action: • Extract the tool name and arguments. • Call the corresponding tool. • Add the tool’s result back into the context. • Ask the model again, now with the tool result included.
- If the response indicates a final answer: • Return that answer and stop.
You might keep a conversation_history list or string that you append to at each step.
- Parsing the Model’s Response: • The model’s response can be parsed by simple string operations or regular expressions. • For instance, you might look for lines starting with Thought:, Action:, and Final Answer:.
A simple regex approach:
Core Components
- Reasoning Engine: Advanced language model with strategic planning capabilities
- Memory Management: Contextual memory retention
- Feedback Loop: Continuous learning and adaptation
Example Pseudo-Architecture
import os
import re
import openai # Assuming using OpenAI API; otherwise integrate your model.
openai.api_key = os.getenv("OPENAI_API_KEY")
# Define tools
def search_func(query):
# Implement a dummy search or integrate a real search API.
# For now, hardcode some results or mock them.
if "capital of France" in query:
return "The capital of France is Paris."
return "No results found."
def calculator_func(expression):
# Evaluate the expression safely
try:
return str(eval(expression))
except:
return "Error in calculation."
tools = {
"search": Tool("search", search_func, "Search the web"),
"calculator": Tool("calculator", calculator_func, "Perform calculations")
}
def call_model(system, conversation_history):
# conversation_history: a list of messages/dicts or a single string
# For OpenAI, format messages as a list of {role: "system"/"user"/"assistant", content: "..."}
# We'll assume conversation_history is a list of such dicts.
response = openai.ChatCompletion.create(
model="gpt-4",
messages=conversation_history,
temperature=0
)
return response.choices[0].message["content"]
def run_agent(user_query):
# Initialize conversation
system_instructions = """
You are an assistant that can use tools.
Always follow this format:
Thought: <your reasoning>
If you need a tool, write:
Action: tool_name | tool_input
If you have enough information, write:
Final Answer: <answer>
Available tools:
search: use it for searching information
calculator: use it for arithmetic calculations
"""
conversation = [
{"role": "system", "content": system_instructions},
{"role": "user", "content": user_query}
]
while True:
model_response = call_model(system_instructions, conversation)
conversation.append({"role": "assistant", "content": model_response})
# Parse response
action_match = re.search(r"Action:\s*(\w+)\s*\|\s*(.*)", model_response)
final_answer_match = re.search(r"Final Answer:\s*(.*)", model_response)
if final_answer_match:
# We got the final answer
return final_answer_match.group(1).strip()
if action_match:
tool_name = action_match.group(1)
tool_args = action_match.group(2).strip()
if tool_name not in tools:
# The model requested a tool that doesn't exist.
# Decide what to do: return an error or tell the model
error_msg = f"Tool {tool_name} not found."
conversation.append({"role": "assistant", "content": f"Thought: {error_msg}"})
continue
# Run the tool
tool_result = tools[tool_name].run(tool_args)
# Provide the tool result back to the model
tool_feedback = f"Tool {tool_name} returned: {tool_result}"
conversation.append({"role": "assistant", "content": tool_feedback})
# The loop continues, and the model can now use this info.
# Example usage:
answer = run_agent("What is the capital of France? Then provide the population of that city.")
print("Agent answer:", answer)Example 2
class AgenticWorkflow:
def __init__(self, goal, initial_context):
self.goal = goal
self.context = initial_context
self.reasoning_engine = AdvancedReasoningModel()
self.memory_bank = ContextualMemory()
def execute(self):
plan = self.reasoning_engine.generate_plan(self.goal)
while not plan.is_complete():
next_action = plan.get_next_action()
result = self.perform_action(next_action)
self.memory_bank.update(result)
plan.adjust(result)
return self.memory_bank.get_final_outcome()Future work
-
Refinements: • Add error handling and retries. • Improve the prompt formatting and instructions to the model. • Store previous reasoning steps or search results in memory structures. • Consider limiting the number of iterations to prevent infinite loops. • Implement a more robust parsing strategy (for example, by requesting structured JSON responses from the model).
-
Extending the Agent: • Add more tools (APIs, databases, file operations). • Introduce “memory” that accumulates long-term context. • Experiment with better prompting techniques, like explicitly asking the model to outline its reasoning steps before producing actions. • Add logging and debugging facilities to trace the agent’s reasoning.
References: