Teach a neural network to mimic an XOR gate
Input: [0,0] → Output: 0
Input: [0,1] → Output: 1
Input: [1,0] → Output: 1
Input: [1,1] → Output: 0
1. CREATE THE DATA
X = torch.tensor([[0., 0.], [0., 1.], [1., 0.], [1., 1.]]) # Inputs
y = torch.tensor([0., 1., 1., 0.]) # Expected outputs
print("Training Data:")
for i in range(4):
print(f"Input: {X[i].tolist()} → Expected: {y[i].item()}")Input: [0.0, 0.0] → Expected: 0.0
Input: [0.0, 1.0] → Expected: 1.0
Input: [1.0, 0.0] → Expected: 1.0
Input: [1.0, 1.0] → Expected: 0.02. Network Design
Network have input layer, hidden layer and output layer.
Why XOR requires a hidden layer? For more information refer this blog AND Vs XOR using NN.
class XORGateNetwork(nn.Module):
def __init__(self):
super().__init__() # Calls the parent class constructor.
self.hidden = nn.Linear(2, 2) # 2 inputs → 2 hidden nodes
self.output = nn.Linear(2, 1) # 2 hidden nodes → 1 output node
def forward(self, x): # Forward pass passes the input through the network and initializes weights and biases.
hidden = torch.sigmoid(self.hidden(x))
output = torch.sigmoid(self.output(hidden))
return output # Return outputs
model = XORGateNetwork()3. Network TRAINING
criterion = nn.MSELoss() # Mean Squared Error
optimizer = optim.SGD(model.parameters(), lr=1.0) # Stochastic Gradient Descent
print(f"\nInitial weights:")
print(f"Hidden layer weights: {model.hidden.weight.data}")
print(f"Hidden layer bias: {model.hidden.bias.data}")
print(f"Output layer weights: {model.output.weight.data}")
print(f"Output layer bias: {model.output.bias.data}")Hidden layer weights: tensor([[ 0.4717, 0.2041], [-0.5889, 0.2877]])
Hidden layer bias: tensor([-0.5101, 0.2829])
Output layer weights: tensor([[-0.4652, -0.1613]])
Output layer bias: tensor([0.5126])4. TRAINING LOOP
losses = []
print("\n🔄 Training...")
for epoch in range(100):
# Forward pass
predictions = model(X).squeeze()
loss = criterion(predictions, y)
# Backward pass
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
if epoch % 20 == 0:
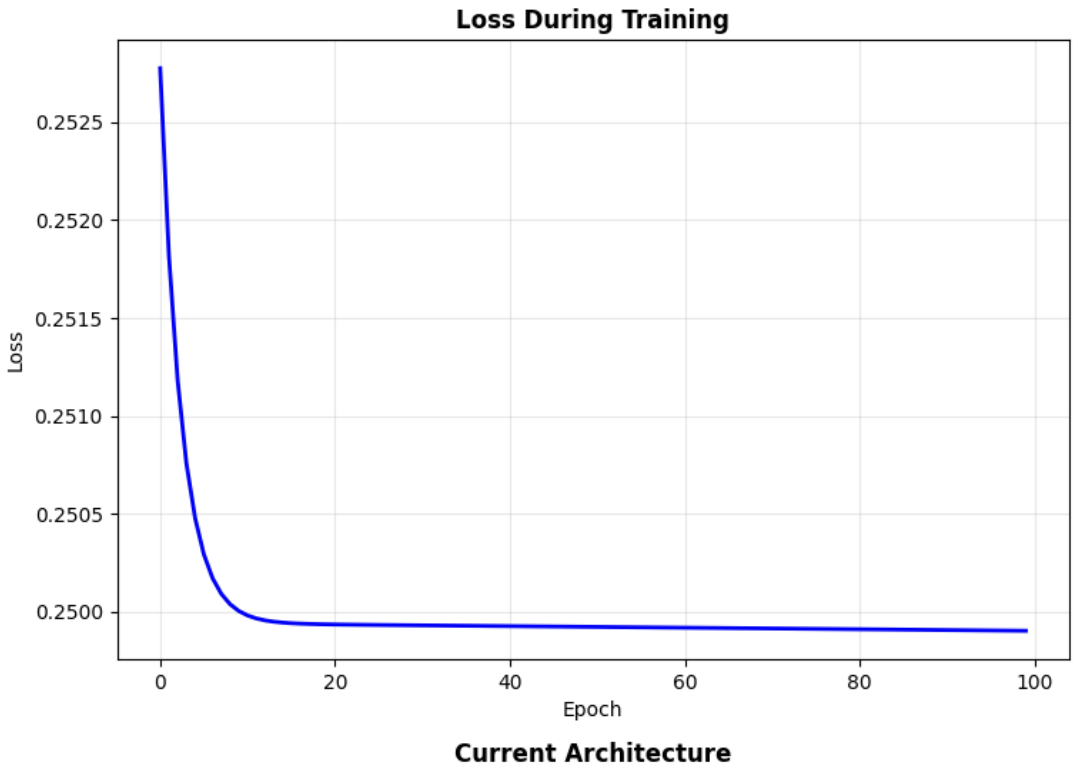
print(f"Epoch {epoch:3d}: Loss = {loss.item():.4f}")🔄 Training...
Epoch 0: Loss = 0.2528
Epoch 20: Loss = 0.2499
Epoch 40: Loss = 0.2499
Epoch 60: Loss = 0.2499
Epoch 80: Loss = 0.2499
# 5. TEST THE LEARNED MODEL
print("\n🎯 Final XOR Results:")
with torch.no_grad():
for i in range(4):
pred = model(X[i:i+1]).item()
expected = y[i].item()
print(f"Input: {X[i].tolist()} → Predicted: {pred:.3f} → Expected: {expected}")🎯 Final XOR Results:
Input: [0.0, 0.0] → Predicted: 0.508 → Expected: 0.0
Input: [0.0, 1.0] → Predicted: 0.497 → Expected: 1.0
Input: [1.0, 0.0] → Predicted: 0.503 → Expected: 1.0
Input: [1.0, 1.0] → Predicted: 0.491 → Expected: 0.0
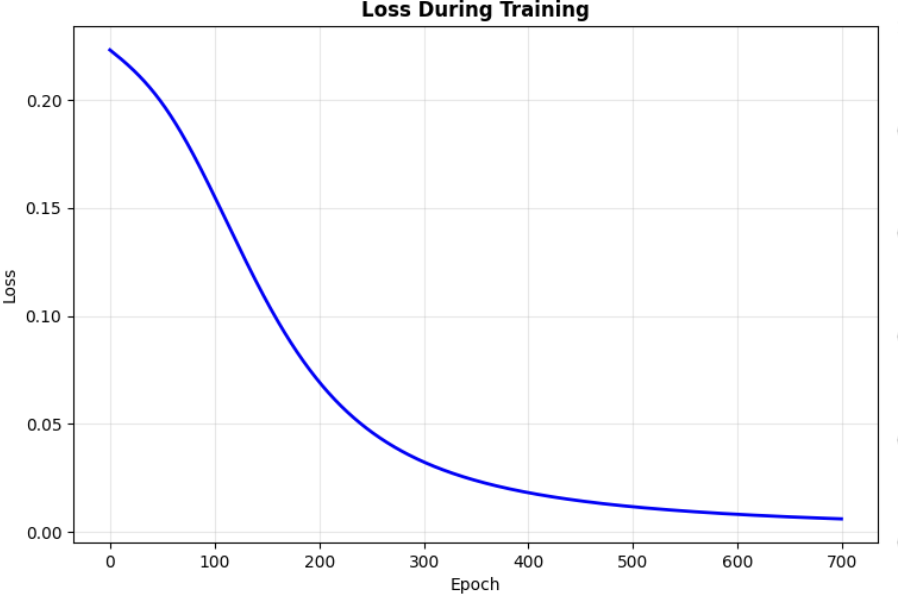
Prediction is way off from what is expected.
 _Figure1:
_Figure1:
Fine tuning to Improve prediction
The high error you’re seeing (predictions around 0.5 instead of 0 or 1) indicates the network hasn’t learned XOR properly yet. It’s a challenging problem that requires careful tuning. Some of the reason with high error in predictions are.
- Small dataset - only 4 examples
- Sensitive to initialization - random weights matter a lot
- Learning rate critical - too high/low prevents convergence
Lets just increase training epochs from 100 to 5000, and see what happens.
for epoch in range(5000):Epoch 0: Loss = 0.0015
Epoch 1000: Loss = 0.0011
Epoch 2000: Loss = 0.0009
Epoch 3000: Loss = 0.0008
Epoch 4000: Loss = 0.0007
🎯 Final XOR Results:
Input: [0.0, 0.0] → Predicted: 0.023 → Expected: 0.0
Input: [0.0, 1.0] → Predicted: 0.974 → Expected: 1.0
Input: [1.0, 0.0] → Predicted: 0.974 → Expected: 1.0
Input: [1.0, 1.0] → Predicted: 0.021 → Expected: 0.0
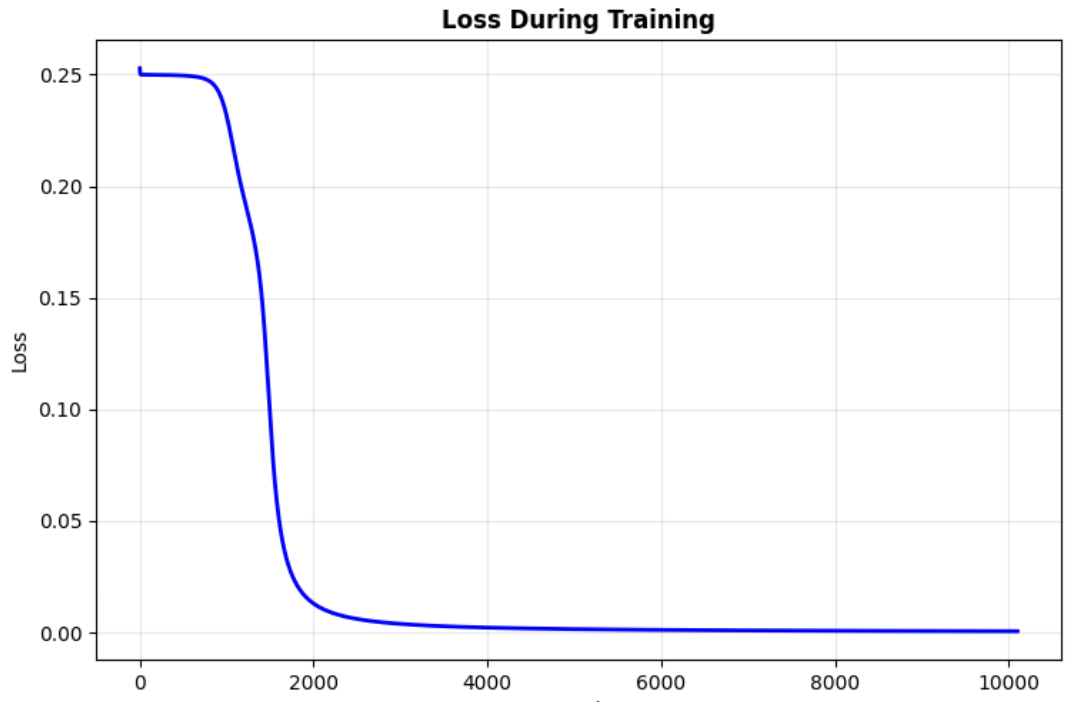 Figure2:
Figure2:
If you compare Figure 1 and Figure 2, losses. You can see with current hyper parameters it takes more epochs to get to good prediction. Increase in number of Epoch may be naive approach which works but not computationally efficient. Lets find out if we can keep the original epochs to 100 and improve learning by changing some other hyper parameter.
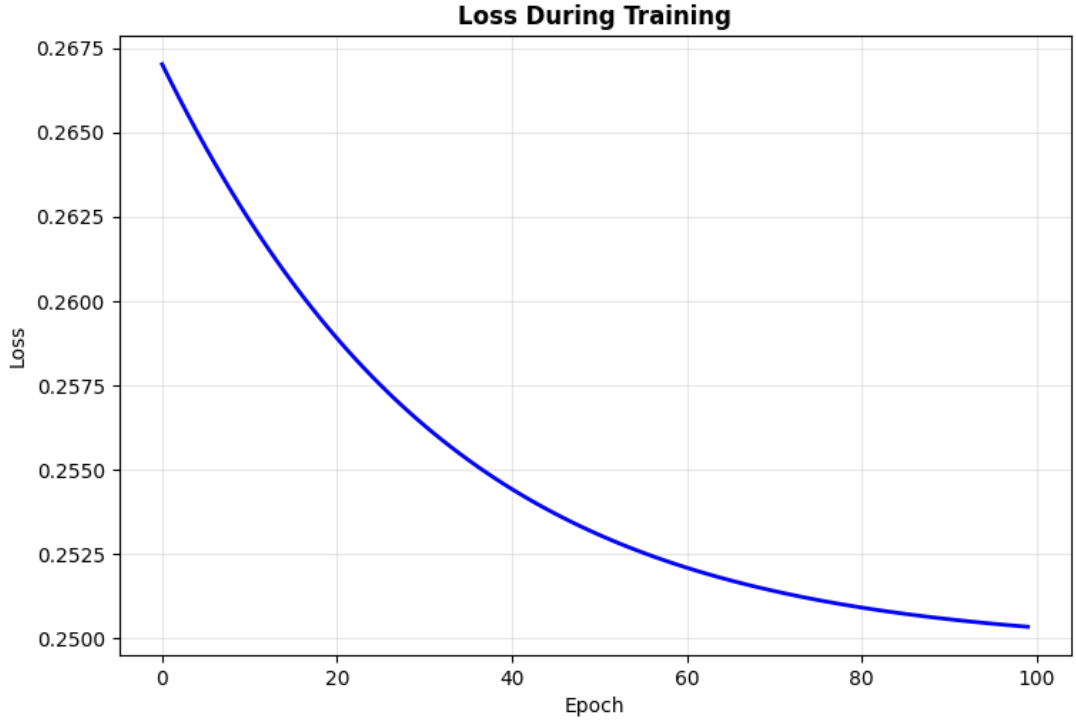
Update learning rate from 1 to 0.1 for Stochastic Gradient Descent
And still our NN prediction is bad
Input: [0.0, 0.0] → Predicted: 0.498 → Expected: 0.0
Input: [0.0, 1.0] → Predicted: 0.483 → Expected: 1.0
Input: [1.0, 0.0] → Predicted: 0.517 → Expected: 1.0
Input: [1.0, 1.0] → Predicted: 0.499 → Expected: 0.0
Setup training with Adam optimiser and quadratic cost
# SETUP TRAINING WITH BETTER PARAMETERS
epoch = 300
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam optimizerInput: [0.0, 0.0] → Predicted: 0.406 → Expected: 0.0
Input: [0.0, 1.0] → Predicted: 0.678 → Expected: 1.0
Input: [1.0, 0.0] → Predicted: 0.381 → Expected: 1.0
Input: [1.0, 1.0] → Predicted: 0.390 → Expected: 0.0