Quote
The purpose of the activation function is to introduce non-linearity into the network … without a non-linear activation function … the network would behave just like a single-layer perceptron (). And: Without non-linear activation function there is no need of deep network because a combination of linear functions can be reduced to a single linear function.
What happens without an activation function (or using linear ones)
Consider a neural network built of layers where every single layer is purely linear. That is, each neuron just does: with no nonlinearity in between.
- Layer 1:
- Layer 2:
- And so on… You can see by induction that a composition of linear transformations is itself a linear transformation. So no matter how many layers you stack, the whole network reduces to one big linear map from input to output. That means:
- You lose all depth advantage.
- You cannot model any non-linear relationships.
- You might as well have a single-layer linear model (e.g. logistic regression or linear regression, depending on loss) to achieve exactly the same result.
Thus, to gain expressive power — to approximate complex, nonlinear functions — we must break this linearity somewhere. That’s exactly what activation functions (nonlinear ones) do.
Why do we need activation function in neural network?
Beyond just nonlinearity, activation functions serve several practical and theoretical roles:
- Allow modeling of nonlinear patterns Real-world data (images, audio, language, sensor data) often has patterns that are nonlinear: boundaries, curves, interactions. Activation functions let the network fit such patterns.
- Enable gradient-based learning (backpropagation) A good activation function is differentiable. That lets us compute gradients (via chain rule) and update weights. If an activation is non differentiable everywhere, training by gradient descent becomes problematic.
- Control signal scale and stability Activation functions (especially bounded ones like sigmoid or tanh) can help restrain large values, keep signals in a controlled range, and avoid numerical blowups. They impose nonlinear “squashing” or rectification which helps stabilize training.
- Introduce saturations, thresholds, sparsity, etc. Depending on the design, activations can impose thresholds (e.g. zeroing out negatives), encourage sparse activations, or selectively “turn off” neurons. That helps in modularity and representational efficiency.
- Universal approximation A theoretical guarantee: networks with at least one hidden layer using non‐polynomial activation functions (like sigmoid, ReLU) can approximate any continuous function on a compact domain (given enough neurons). This is the universal approximation theorem.
How activation function learns non linearity? Or What it means to learn nonlinearity?
Imagine trying to approximate a curve (say, a sine wave) using only straight line segments. If you only use straight lines with no ability to bend, your approximation is very limited. But if you allow “bend points” — nonlinear segments — you can piecewise fit the curve more closely.
In a neural network:
- The weights + biases define linear transforms.
- The activation functions let you “bend,” “threshold,” or “wrap” the signal, injecting nonlinearity. Thus, each neuron becomes a little nonlinear unit, and stacking many lets you carve out very flexible shapes in input space.
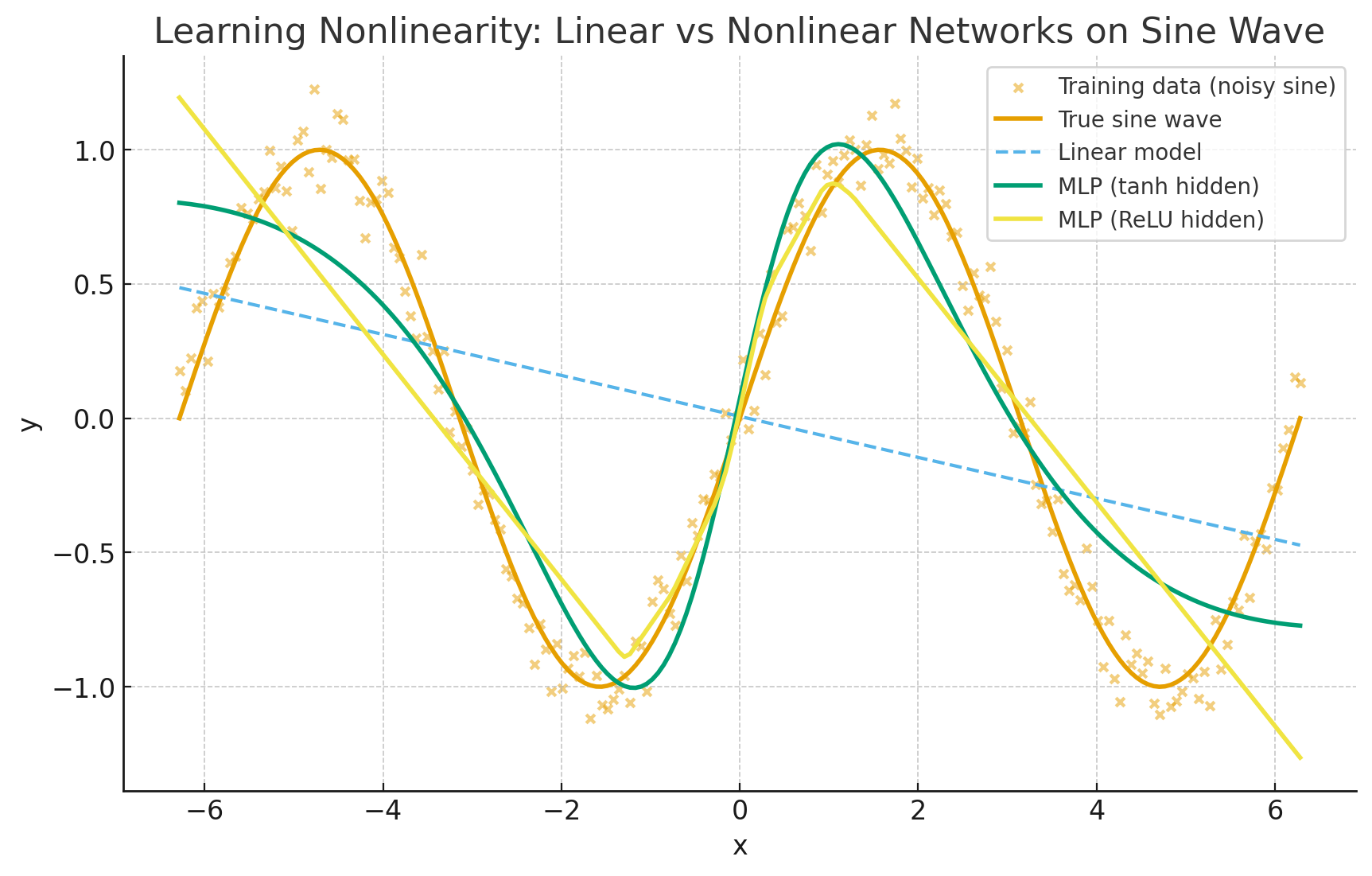 MLP with tanh/ReLU hidden layer: bends and warps input space → learns the oscillations and tracks the sine wave much more closely.
MLP with tanh/ReLU hidden layer: bends and warps input space → learns the oscillations and tracks the sine wave much more closely.
How does the network learn this nonlinearity?
- Each hidden neuron applies:
- Linear part = projection
- Nonlinear part
- With training (via gradient descent), the network adjusts weights so that after nonlinear activations, the transformed space separates classes.
- Stacking layers = multiple nonlinear transformations → increasingly complex “warping” of input space.
Different activation functions.
Choosing a good activation function matters for learning dynamics, expressivity, and convergence.
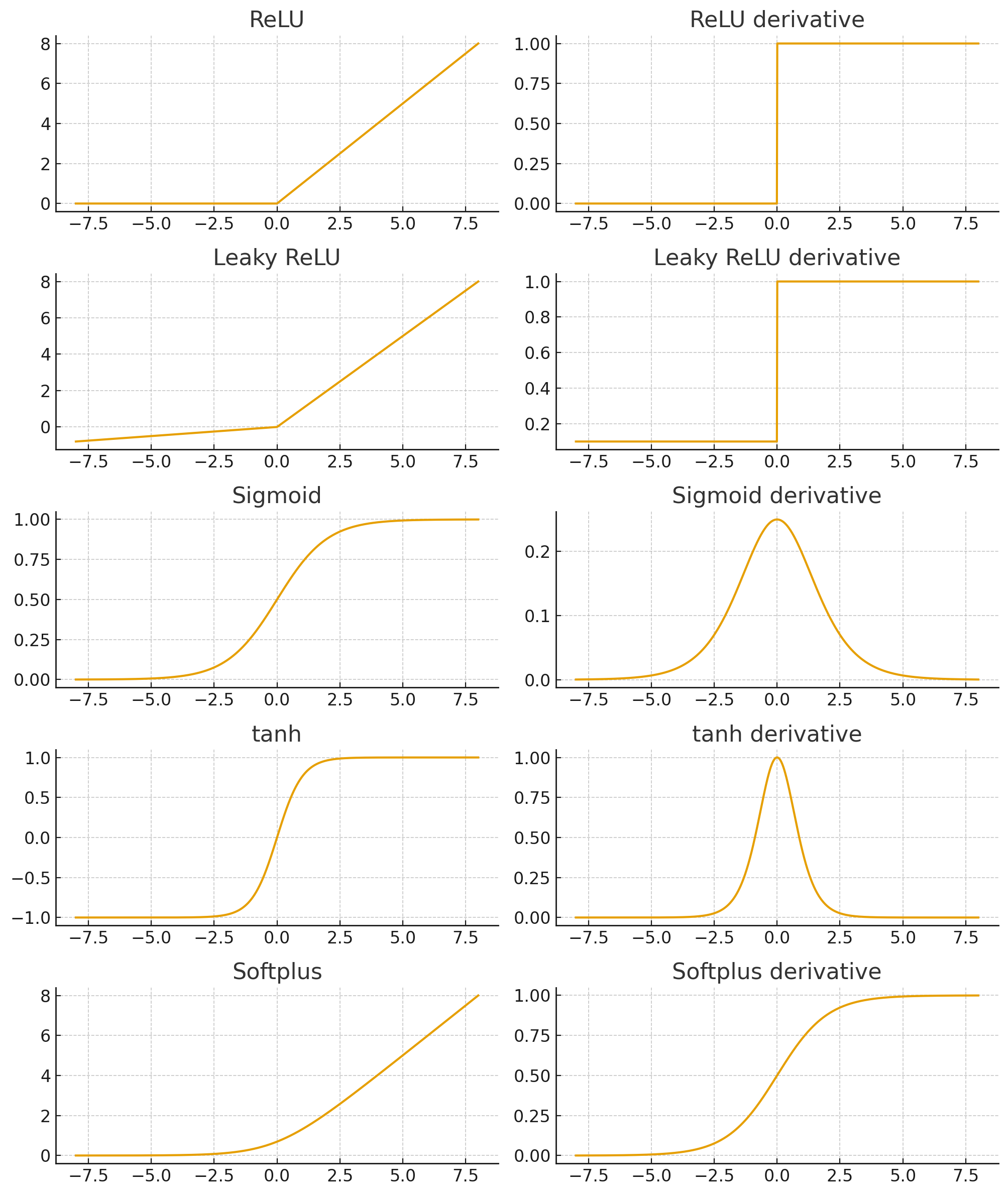
ReLU (Rectified Linear Unit)
So:
- If , output = x.
- If , output = 0.
- Derivative: = 1 for x > 0, and 0 for x < 0.
Key properties
- Sparse activation / “natural sparsity” Because negative inputs map to zero, many neurons will output zero, effectively “inactive,” which leads to a sparser representation and can help with efficiency or preventing overfitting.
- Computational simplicity It’s extremely cheap: just a threshold, no exponentials, no divisions, etc.
- Better gradient flow in deep networks Because the positive side is linear, gradient doesn’t vanish as layers increase. Empirically, using ReLU often accelerates convergence in deep nets compared to sigmoid/tanh.
- Biological plausibility (loose analogy) Some argue that neurons in biological brains don’t produce negative firing rates, so a rectified function is more plausible, though this is only a rough analogy.
Limitations & pitfalls (“Dying ReLU”, etc.)
- Dead / “dying ReLU”: If a neuron’s input becomes negative consistently and the weights update push it further negative, it can become stuck outputting zero forever (gradient = 0). Then it never recovers.
- No negative output: This means the activation is not zero-centered, which sometimes slows convergence or introduces bias shift. (Because all activations are nonnegative, subsequent layers may have biased inputs.)
- Unbounded output: Because for large x, output = x, there is no explicit bound, which may allow extremely large activations that need normalization (batch norm, etc.).
Because of these, many ReLU variants exist (Leaky ReLU, PReLU, etc.) that attempt to mitigate dying ReLUs.
Sigmoid function
- Output of sigmoid is always in (0,1).
- Often interpreted as the probability of the “positive” class.
- Works great if you only have two classes . 👉 But if you have K > 2 classes, just applying sigmoid to each logit doesn’t enforce they sum to 1. Each neuron independently decides “am I on or off?” — no competition.
Why sigmoid at the output doesn’t form a probability distribution
If you put a sigmoid on each of, say, 3 output neurons:
- Each entry is in (0,1).
- But the sum could be anything — e.g. 0.3 + 0.8 + 0.6 = 1.7 (invalid as probabilities).
- You can’t directly interpret them as “probability that input belongs to class 1, 2, or 3.” 👉 With sigmoid outputs, activations don’t naturally form a probability distribution**.
Softmax function
The softmax function takes a vector of raw scores (called logits, e.g. outputs of the last linear layer of a neural network) and converts them into a probability distribution.
Why do we need it?
- Neural networks end with numbers that can be positive or negative (logits).
- For classification, we need outputs that look like probabilities:
- Non-negative
- Sum to 1
- Linear outputs don’t satisfy this. Sigmoid works for binary class, but for multi-class, we need a generalization → softmax.
- Softmax probabilities are often paired with cross-entropy cost.
- This pairing has a special property: it simplifies gradients (avoids extra sigmoid-like shrinkage), making learning faster and numerically stable
Why not just normalize logits by dividing each by the sum of absolute values?
That wouldn’t preserve the exponential “competition” property; large logits should dominate more sharply than small ones.
Where is softmax applied in the network?
- Only at the output layer (in standard feedforward classifiers).
- Earlier layers use other activation functions (ReLU, sigmoid, tanh, etc.), because we don’t want every hidden neuron’s outputs to behave like a probability distribution.
- At the final layer, we want to map raw scores → probabilities, because classification = probability assignment.
Why not apply it everywhere throughout network?
If you applied softmax at every layer:
- Every hidden layer would force its outputs to sum to 1 → losing expressive power.
- Neurons couldn’t freely learn features, because they’d always be competing to form a probability distribution instead of just passing useful signals.
- Training would be unstable and inefficient. 👉 That’s why softmax is reserved for the final classification layer.
How softmax converts raw score into probability distribution?
Suppose the network outputs arbitrary real numbers: These numbers can be negative or positive and have no constraint (they don’t add to 1). Clearly, they can’t be treated directly as probabilities.
Exponentiation
Larger logits get disproportionately larger after exponentiation → it sharpens differences between classes. Softmax first applies the exponential:
- This makes everything positive (good: probabilities can’t be negative).
- It also amplifies differences — larger logits grow disproportionately bigger.
Normalization (divide by the sum)
Now divide each term by the total sum:
Here, denominator = 8.17+0.22+1.35=9.74 So probabilities are:
Intuition: Human brain parallel
Imagine you’re picking which dessert to eat: cake (score 3), fruit (score 1), or cookie (score 2).
- If you just picked max → always cake.
- But your brain sometimes explores alternatives.
- Softmax gives probabilistic preference:
- Cake 70%, Cookie 20%, Fruit 10%.
This balance between exploitation (pick best) and exploration (sometimes others) mirrors decision-making in brains.
- Cake 70%, Cookie 20%, Fruit 10%.
✅ Summary intuition:
- Raw logits are “scores” saying how strong each class looks.
- Earlier layers are “feature extractors” → they shouldn’t be forced into probability distributions.
- Final layer = “decision-maker”
- Softmax = “competition game” among output neurons.
- Exponentiation sharpens competition.
- Normalization turns those sharpened scores into probabilities.
Comparing Sigmoid Vs Softmax
When to use which
- Sigmoid: binary classification (yes/no, spam/not spam).
- Softmax: multi-class classification (digit recognition 0–9, image category).
- Sigmoid with multiple outputs (independent): multi-label problems (e.g., “this photo contains dog=1, cat=1, car=0”). Here probabilities don’t need to sum to 1, because labels aren’t mutually exclusive.
We’ll compare sigmoid + cross-entropy (binary case) vs softmax + cross-entropy (multi-class case).
Sigmoid with cross-entropy (binary classification)
- Prediction:
- Cross-entropy loss:
- Gradient wrt logit : ✨ Notice: no extra σ′(z)σ′(z) term, because the derivative of sigmoid cancels with cross-entropy. This avoids vanishing gradients at the output layer.
Softmax with cross-entropy (multi-class classification)
- Prediction for class :
- Cross-entropy loss:
- Gradient wrt logit : ✨ Exactly the same simple form as sigmoid case! No messy chain rule terms survive — the math collapses nicely.
Why this is powerful
- Without cross-entropy, gradients involve sigmoid’(z) or softmax Jacobian, which shrink and cause vanishing gradients.
- With cross-entropy, the gradient becomes a simple difference between predicted and true probability.
- This gives stable, strong learning signals, especially at the output layer
Why sigmoid is local and softmax is not?
Sigmoid (locality property)
For the sigmoid:
- Each output depends only on its own input .
- Change (for some ) → it does not affect .
- This is why we say sigmoid is local: every neuron is independent.
Softmax (non-locality property)
For the softmax:
- The numerator uses .
- But the denominator includes all logits .
- So, if you change any the denominator changes, and thus changes too. 👉 That’s why softmax is non-local: the output probability for one class depends on all the others.
Why sigmoid and softmax curves are same?
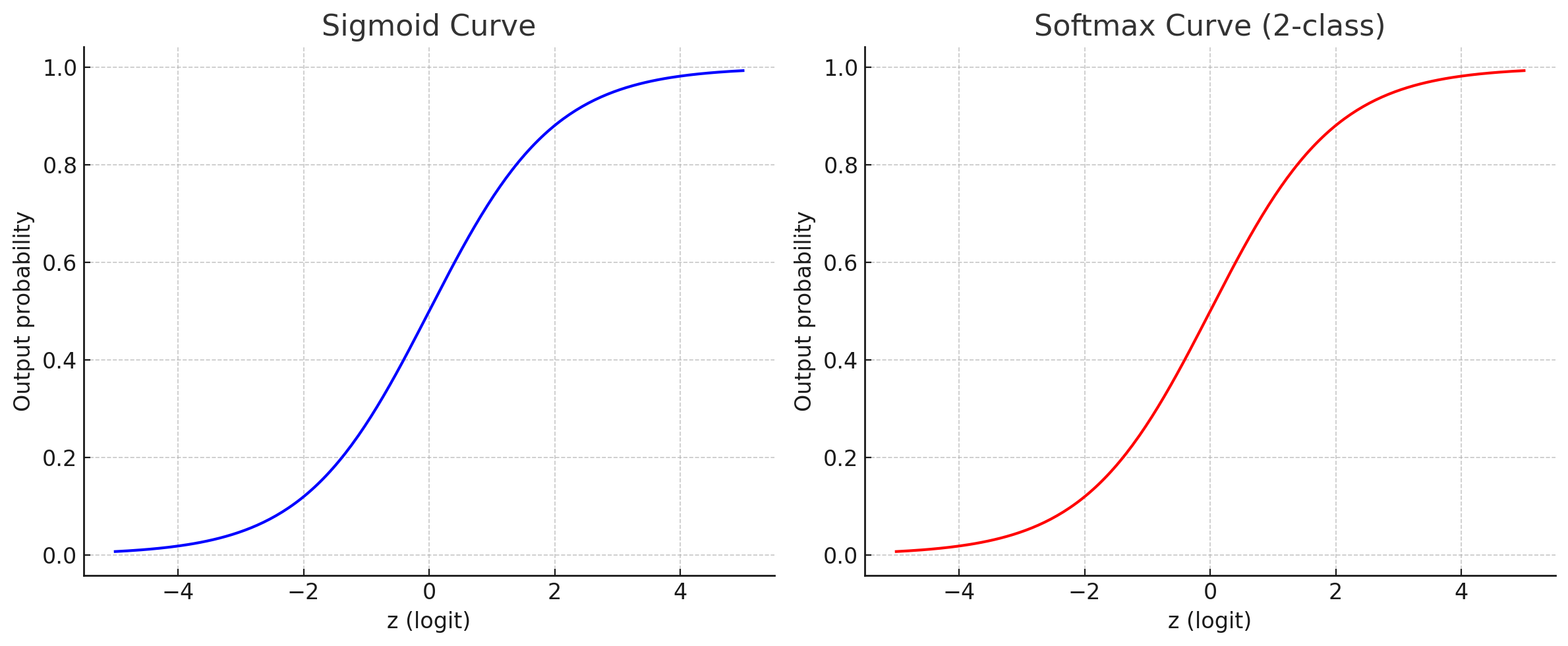
They look identical because softmax reduces to sigmoid in the binary case.
With 2 classes, softmax essentially computes:
👉 That’s why the curves overlap: sigmoid is just the special case of softmax with two classes.